Memory Allocation in Zig
As I continue to get my feet wet with Zig, I find myself greatly admiring the paradigm of no hidden allocations1. Any function that needs to allocate heap memory must receive a mem.Allocator2. This is more explicit than the ability to call malloc() at any depth of the call stack in C and lets (and forces) the calling code decide what allocator to use. So on the other hand, the programmer generally knows that any function without an Allocator argument only uses stack memory, though of course nothing stops a Zig function from initializing a new Allocator. This is not a guarantee, but at least there is a blessed pattern for it.
Working with Netlink
In my previous post, I mentioned working on a Netlink library in Zig. Pretty much every Netlink library I have seen manages an internal byte buffer for communication with the kernel, and mine is no different.
const std = @import("std");
const os = std.os;
pub const Handle = struct {
buf: []u8,
sk: os.socket_t,
fn recv(self: Handle) os.RecvFromError![]u8 {
const n = try os.recv(self.sk, self.buf, 0);
return self.buf[0..n];
}
}
pub fn main() !void {
var buf = [_]u8{0} ** 4096;
var sk = try os.socket(linux.AF.NETLINK, linux.SOCK.RAW, linux.NETLINK.ROUTE);
defer os.close(sk);
var nlh = nl.Handle.init(sk, &buf);
// send a request
var response = try nlh.recv();
// parse the response
}
Programs that use Netlink often make multiple request+response roundtrips to the kernel. The buffer is of course necessary for the recv() call, and it is more efficient to reuse the buffer than create a new one for each response.
Because the Handle.recv() function does not receive an Allocator (or create its own), I know it does not allocate heap memory. The code above is just a sample; the real Handle.recv() method also parses the response according to the Netlink protocol, but it also does not receive an Allocator. The parsing code effectively casts sections of the buffer to structure pointers:
const LinkListResponse = struct {
hdr: *linux.nlmsghdr, // same value as `Handle.buf.ptr`
middle: *linux.ifinfomsg, // `Handle.buf.ptr + @sizeOf(linux.nlmsghdr)`
attrs: []u8, // everything else up to `nlmsghdr.len`
}
This design means the parser can not only avoid copying segments of the response bytes into a heap-allocated structure, but it also minimizes stack usage since it only allocates pointers rather than the entire nlmsghdr and ifinfomsg types. Though in this case those types are so small it’s hardly a notable difference.
Memory Profile
Can I prove it? I wrote a small program to send a RTM_GETLINK request with the NLM_F_DUMP flag 100 times in serial, i.e. return all the current network devices. The response is parsed to find an print the highest MTU of all the devices, which I’m only doing to make sure the parser is exercised and correct. The program is hardly different from the example code committed to that repo3, so I won’t include it here.
I would usually use valgrind for this, but I was curious to try out a newish tool called heaptrack4.
$ heaptrack ./zig-out/bin/example-link-list
...
heaptrack stats:
allocations: 1
leaked allocations: 0
temporary allocations: 1
If the sending, receiving, and parsing code were allocating memory on the heap, these numbers would at least need to be over 100.
The heaptrack GUI shows peak memory usage and notes the sources of each allocation:
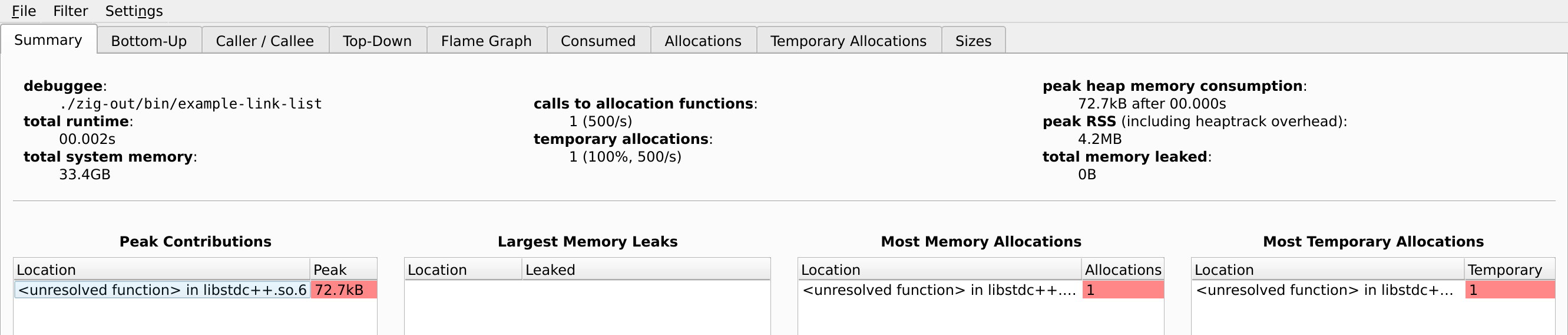
Comparison with Rust
This isn’t a comparison with Rust the language, just it’s most popular Netlink library5. Nothing about the Rust language prevents controlling dynamic memory allocation, though it’s certainly not a common concern based on the language design. Standard library types such as Vec6 are being fit with an Allocator trait, see https://github.com/rust-lang/rust/issues/32838.
Using the netlink-packet-route7 crate and its neighbors, I wrote a small Rust program to list links just like the Zig one.
pub struct Handle {
buf: Vec<u8>,
socket: netlink_sys::Socket,
}
impl Handle {
fn talk_dump(&mut self, mut msg: NetlinkMessage<RtnlMessage>) -> Result<u32, Error> {
msg.header.sequence_number = 1;
msg.finalize();
self.buf.clear();
self.buf.reserve(msg.buffer_len());
unsafe { self.buf.set_len(msg.buffer_len()) };
msg.serialize(self.buf.as_mut_slice());
let sent = self.socket.send(self.buf.as_slice(), 0)?;
assert_eq!(sent, self.buf.len());
let mut mtu: u32 = 0;
loop {
self.buf.clear();
unsafe { self.buf.set_len(self.buf.capacity()) };
let size = self.socket.recv(&mut self.buf.as_mut_slice(), 0)?;
unsafe { self.buf.set_len(size) };
let mut i: usize = 0;
while i < self.buf.len() {
let msg = <NetlinkMessage<RtnlMessage>>::deserialize(&self.buf.as_slice()[i..])?;
match msg.payload {
NetlinkPayload::Done(_) => return Ok(mtu),
NetlinkPayload::Error(msg) => return Err(Error::Io(msg.to_io())),
NetlinkPayload::InnerMessage(msg) => {
match msg {
RtnlMessage::NewLink(link) => {
for attr in link.nlas.iter() {
match attr {
Nla::Mtu(m) => mtu = *m,
_ => {},
}
}
}
_ => return Err(Error::UnexpectedPayload(format!("{msg:?}"))),
}
},
p => return Err(Error::UnexpectedPayload(format!("{p:?}"))),
}
i += msg.header.length as usize;
}
}
}
pub fn links(&mut self) -> Result<u32, Error> {
let mut msg = NetlinkMessage::new(
NetlinkHeader::default(),
NetlinkPayload::from(RtnlMessage::GetLink(LinkMessage::default())),
);
msg.header.flags = NLM_F_ACK | NLM_F_DUMP | NLM_F_REQUEST;
let mtu = self.talk_dump(msg)?;
Ok(mtu)
}
}
It is certainly not the best Rust code, but I don’t think anything here takes away from point I’m making. The main() function will call Handle.links() 100 times in a loop just like the Zig program.
$ heaptrack target/release/rtnl
heaptrack stats:
allocations: 10513
leaked allocations: 0
temporary allocations: 2701
Woah, that’s quite a bit more by comparison, but it hasn’t impacted the peak memory usage at all:
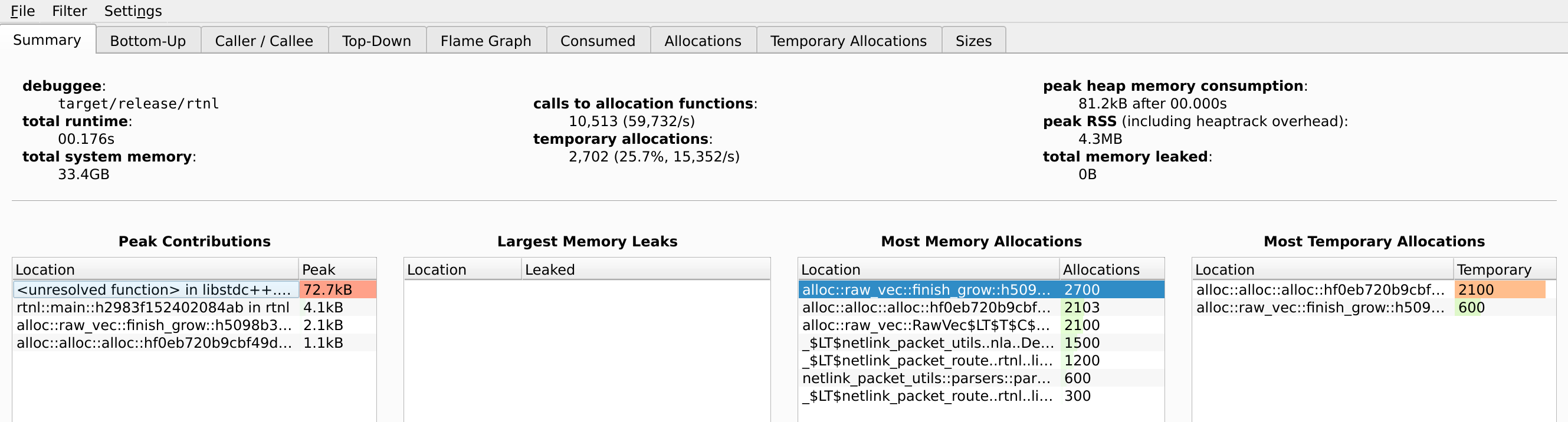
Heaptrack also has a flamegraph to show where the allocations are happening:
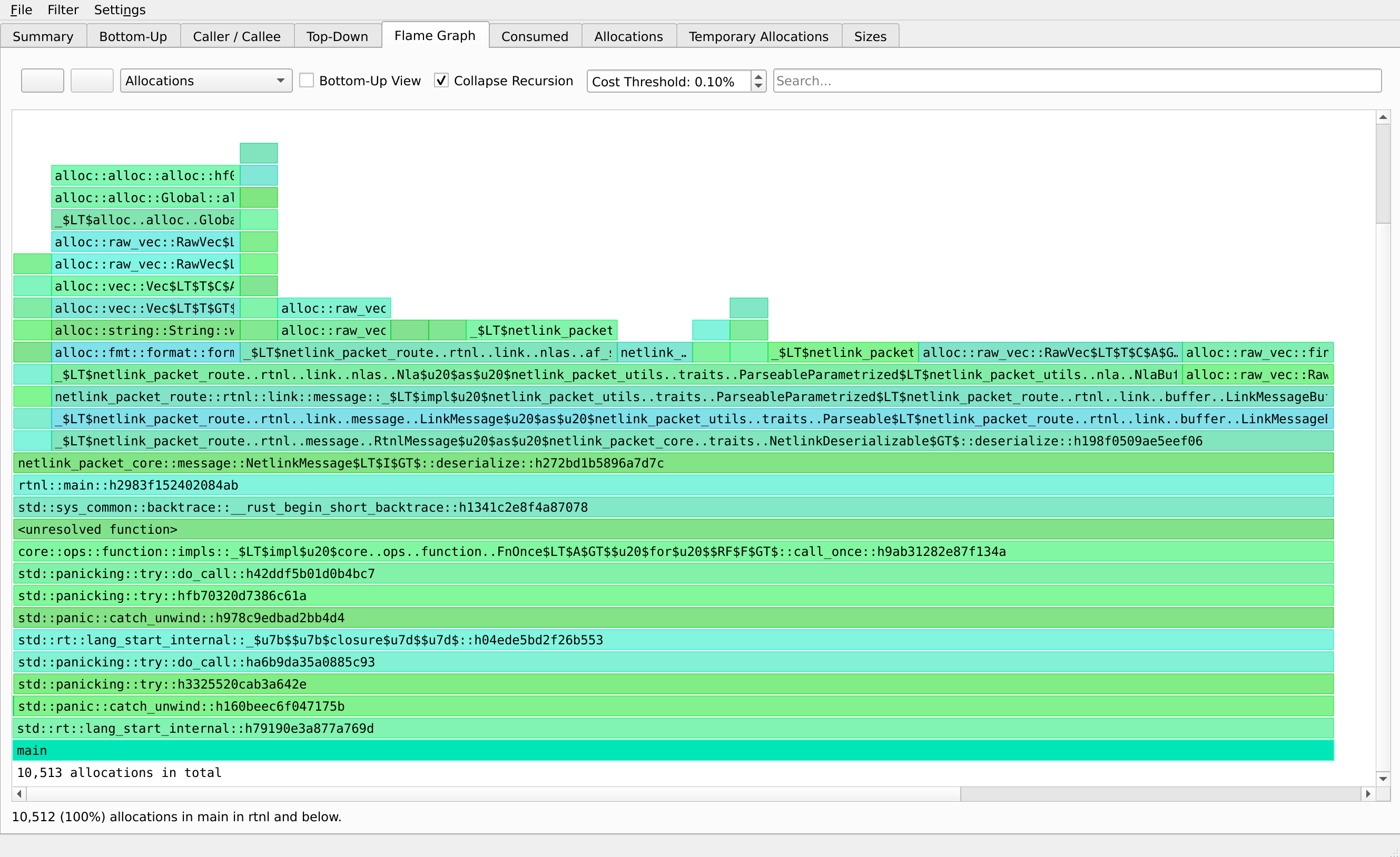
I know the image is hard to make out, but 99.9% of allocations happen in the NetlinkMessage::deserialize() method8, and 97% of all allocations are made while parsing the Netlink link attributes9. There are two culprits here: the first being that the attributes are stored in a Vec, and the second that some of the attributes are parsed into Strings. Both of these structures use the heap to allocate memory as they have a dynamic length.
Now again, this is an outcome of the way the crate was written, and not entirely inherent to the Rust language itself. However, if writing a Zig library that performed the same parsing, it would be natural to define the function as
const NetlinkMessage = struct {
fn deserialize(allocator: mem.Allocator, buf: []u8) !NetlinkMessage {
}
}
And then the caller could write
var buf = [_]u8{0} ** 4096;
var allocator = std.heap.FixedBufferAllocator.init(buf);
const msg = NetlinkMessage.deserialize(allocator, response);
This is the beauty of explicity allocators. Even though some library methods need to dynamically allocate memory, the programmer actually decides where that memory comes from. Hopefully Rust will get there eventually, but Zig encourages this pattern from the get-go. Just like C, it forces the programmer to think about memory. Of course, that’s not a good thing in all cases; I still like banging out quick scripts in python.
So What?
The bottleneck here is I/O with the kernel, not heap memory. The Zig program comes out a tiny bit faster, but practically it wouldn’t make a difference for a CLI tool like iproute2, which only makes a few requests per execution. A flamegraph from perf record does indeed show that the Rust program spends time in malloc(), realloc() and free() as expected, and none of those functions appear in the Zig program’s flamegraph.
As a broad generalization, memory usage is never a problem until it is. That sounds silly, but it has been my experience working on Linux server software and just generally using computers with a little bit of understanding. You don’t think about memory until a new release goes out and monitoring indicates your memory unexpectedly doubled or you hit a cgroup limit and get OOM-killed. And then you go dig into why your code is allocating an order of magnitude more instances of a data structure that is 3 layers deep in external dependencies. Or you don’t use a streaming json parser and that entire 100MB payload is being stored for awhile just so you can read a kilobyte of data somewhere in the middle. Slack uses several gigs of memory, but it’s not a problem because my laptop has 16 and doesn’t charge rent.
Rant aside, I do really appreciate having a language that feels like it is helping me respect the machine’s memory.
-
https://ziglang.org/learn/why_zig_rust_d_cpp/#no-hidden-allocations ↩︎
-
https://ziglang.org/documentation/0.11.0/std/#A;std:mem.Allocator ↩︎
-
https://docs.rs/netlink-packet-core/latest/netlink_packet_core/struct.NetlinkMessage.html#method.deserialize ↩︎
-
https://docs.rs/netlink-packet-route/latest/netlink_packet_route/rtnl/link/nlas/enum.Nla.html ↩︎